Zasada odwrócenia zależności to zasada, która pokazuje, jak dobrze zaprojektować zależności w naszym kodzie.
Twierdzi następująco:
Wysokopoziomowe moduły nie powinny zależeć od modułów niskopoziomowych. Oba moduły powinny zależeć od abstrakcji.
Abstrakcja nie powinna zależeć od szczegółów, czyli konkretnej implementacji. Z kolei szczegóły powinny zależeć od abstrakcji.

Z zasady tej wynika, że powinna wyłonić się warstwa abstrakcji realizująca interakcję pomiędy modułami, które nie muszą, a nawet niepowinny o sobie nic wiedzieć. Wystarczy, że przystosowują się one do kontraktu dostarczanego przez abstrakcję. Przez kontrakt rozumię tu interfejsy i wewnętrzną spójność obiektu w myśl zasady podstawienia Liskov. Nawet jeżeli moduły nie spełniają kontraktu, to mogą one wykorzystywać dodatkową warstę adaptacji, gdzie to przy użyciu wzorca adaptera moduł będzie mógł realizować obcy sobie kontrakt.

Warstawa abstrakcji powinna być jednak budowana w oparciu o jakieś założenia. Mogą one wynikać z potrzeb warstwy wyższego poziomu, lub oferty warstwy niższego poziom.
Którą drogę wybrać?
Można tu podeprzeć się zasadą Inteface Segregation, która wspomina o tym, że interfejs powinien posiadać tylko takie metody, które rzeczywiście będą używane przez klienta. Z tego można wysnuć, że najlepiej jak interfejs będzie dostarczony w oparciu o potrzeby modułu wyższego poziomu, niż ofertę niższego poziomu.
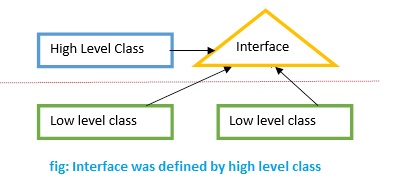
Tak różne kontrakty, tylko jedna implementacja
Jednak istnieje taka możliwość, że nasz moduł niższego poziomu, będzie realizował zadania dla wielu modułów. Każdy z nich może proponować trochę inny kontrakt, jednak potrzebować rozwiązania tych samych problemów. W takich przypadkach najlepiej zastosować wcześniej wspomnianą warstwę adaptacji.

Jednym z przypadków dla zastosowania tej techniki jest korzystanie z API zewnętrznych bibliotek. Nie powinno się uzależniać implementacji klas wysokich poziomów, bezpośrednio od interfejsów, czy klas oferowanych przez bibliotekę. Wywołania API, powinny być adaptowane, do potrzeb klienta. Należy przez to rozumieć również odseparowanie od argumentów takiego wywołania.
Nawet o tym nie myśl!
Podczas implementacji modułu wyższego poziomu, szczegóły implementacji niższego, nie powinny być dla nas istotne. Znajomość lub samo tylko wyobrażenie o implementacji, może przeszkadzać w dobrym projekcie interfejsów i logiki w module nadrzędnym. Może bowiem okazać się, że podświadomie będziemy dążyć do uzależnienia się od fałszywej abstrakcji. To będzie skutkować problemami z podmianą implementacji lub adaptacją odmiennych rozwiązań.
Operator new, oraz statyczne metody.
Jeżeli zastosujemy w jakimś miejscu naszego kodu operator new to powstanie silna zależność od implementacji tworzonego w ten sposób obiektu. Takie same konsekwencje będzie miało również użycie metody statycznej. Tworzenie takiego obiektu, lub wywoływanie takiej metody powinno odbywać się, poza klasą która go używa. W szczególności gdy dotyczy to, klas pochodzących z innych modułów.
Fabryka
Dobrym rozwiązaniem może okazać się użycie wzorca Fabryki. W ten sposób odseparujemy tworzenie obiektu od miejsca jego użycia. Prosta fabryka, nadal jednak będzie silnie związana z szczegółami implementacji.
Rozwiązanie to jest jednak dużo lepsze. To w fabryce będzie umieszczona decyzja, z jaką implementacją będzie związany klient z modułu nadrzędnego. Łatwiej będzie zmienić wybór implementacji w jednym miejscu, niż wiele odwołań przez operator new.
Dodatkowo decyzja o wyborze implementacji może być sterowana, przez klienta, lub statycznych źródeł informacji jak np. dane z pliku konfiguracyjnego aplikacji.
Mockowanie fabryk, na potrzeby testów może odbywać się zaś przez dodatkowy setter, lub konstruktor, i tym miłym akcentem możemy przejść do kolejnej techniki.
Wstrzykiwanie zależności
Innym sposobem odseparowania tworzenia obiektów jest wstrzykiwanie zależności (Depencency Injection), czyli przekazywanie zależnych obiektów, przez konstruktor lub settery. Z reguły powinno używać się konstruktora, wtedy jasno określone są wymagane zależności. Wstrzykiwanie przez setter pozwala na zmianę zależności po utworzeniu obiektu, jednak dopuszcza też możliwość utworzenia obiektu bez wymaganych zależności, co może skutkować wyrzucaniem wyjątków.
Uwaga! Zbyt duża liczba wstrzykiwanych zależności, może świadczyć o realizacji różnych odpowiedzialności w jednej klasie.
Wstrzykiwanie fabryk
Dobry efekt można uzyskać również łącząc dwie powyższe techniki, umożliwiajac wstrzykiwanie obiektów fabryk, w szczególności gdy klient w cyklu swojego funkcjonowania może korzystać z różnych implementacji.
Refleksje
Ciekawym pomysłem może być użycie refleksji w celu tworzenia obiektów według wskazówek z plików konfiguracji np. w postaci nazw docelowych klas. Należy pamiętać, że refleksje mogą znacząco utrudnić analizę kodu.
Kontener IoC
To takie jakby konfigurowalne fabryki, swego rodzaju rejestry. Gdzie możemy ustalić zależności między obiektami.
Dostęp do klas i modułów
Kluczem w utrzymaniu stanu odseparowania od szczegółów, będzie umiejętne zarządzanie dostępem do klas i interfejsów. Elementy niebiorące udziału w komunikacji między modułami powinny być jak najbardziej hermetyzowane, aby nikogo nie kusiło, użycie ich bezpośrednio w innych modułach. Natomiast publiczne powinny być, interfejsy i klasy potrzebne do komunikacji między modułami. Do komunikacji wewnętrznej w module często dobrym rozwiązaniem, może okazać się dostęp w obrębie pakietu. Warto też pomyśleć o narzędziach pozwalających za ustalenie zależnosći między modułami, takimi jak OSGi, Maven lub Gradle.
Dlaczego warto stosować tą zasadę?
- Zwiększona czytelność kodu. Abstrakcja informuje o intencji działania, a szczegóły implementacji nie utrudniają jej zrozumienia.
- Dobra elastyczność. Funkcjonowanie z nieznaną wcześniej implementacją
- Szybsze dostosowania się do nowych wymagań.
- Większą testowalność jednostek. Możliwość mokowania zależności do zewnętrznych modułów.
- Lepsza reużywalność. Implementację bez większego problemu powinniśmy móc przenieść do osobnej biblioteki, aplikacji, lub usługi.
- Łatwiejsze utrzymanie kodu. Błędy wynikające z jednego modułu nie muszą być poprawiane w innych modułach.
